
























 分享文章
分享文章
百度第三代搜索引擎工作原理 百度第三代Spider是什么?
技术
2021-02-15 10:37
声明:该文章由作者(赵宥乔)发表,转载此文章须经作者同意并请附上出处(0XUCN)及本页链接。。
百度第三代Spider是什么?
在过去,百度搜索引擎的数据处理的多数工作是由MapReduce系统完成的,处理延时达到天级。从2014年开始,Spider系统进行了大规模重构,以搜索结果更新延迟从周级缩短到分钟级为目标,设计实现了海量实时数据库Tera。在此基础上,构建了每天实时处理几万亿链接与网页更新的百度第三代Spider系统。
区别于上一代系统,新系统的核心流程全部实时化,从互联网上出现一篇新网页,到基于历史分析与机器学习快速发现链接,到基于链接价值的抓取调度,再到对网页进行分类、筛选每个步骤都在几秒钟内完成,以保证新网页能以分钟级更新到搜索结果中。
也就是说,当互联网上产生一个新的网页时,Spider 2.0把它下载回来的时间大概是2-3天,而Spider 3.0却只需要5分钟,相当于大概是3个量级的提升。
我从一加入百度,就开始构想第三代Spider了,后面的五年几乎都在开发百度Spider第三代系统。因为它是一个非常庞大的业务系统,所以底层需要各种各样的基础架构系统支持,包括分布式文件系统、集群管理系统和数据库系统等等。当前,这些底层系统都已经开源,如果有兴趣可以一起参与进来。
搜索引擎与Spider3.0
首先故事从互联网和搜索引擎开始,大家平时经常接触到的互联网以及百度搜索引擎,很多人也思考过互联网上的网页怎么转化成百度搜索引擎里面这十条结果的。这里面的工作分为很多阶段,如下图所示。最开始,由Spider去做信息采集。
后面的Pagerank其实代表了一系列的计算,包含了反作弊、去重和基于页面质量的筛选等等。此阶段之后会对网页进行切词,计算网页的正排,再做转置变成倒排。最后进入检索系统供网民直接检索。Spider是该系统的起点,它的主要目的就是快速、全面地采集全网数据。那么,全网数据到底是什么概念呢?

大家设想一下,当前中文互联网到底有多少网页?不知道有多少人尝试算过或者估算过,其实我们也不知道具体的数字,但是我们通过搜索引擎估算,结果大概有100万亿的网页。其中高质量的部分大概有10万亿,这10万亿就是百度Spider所要采集网页的核心任务。
但是,光采集回来还不够,还要知道它到底有没有价值。中文互联网每天新增多少网页?100亿,也就是说互联网每天就会产生100亿的新网页。那么会产生多少条超级链接呢?每个网页上会有多少条链接?百度统计的大概结果是,平均一张网页上有120条链接,这不是指特定某个网页上有120条,而是平均值。从这一点就看到整个百度Spider每天要处理的数据量,大概每天要处理1万多亿的链接。
怎么去处理这么大规模的数据,其实在过去有个比较通用的解决方案:Hadoop。基于Hadoop的第二代Spider主要流程如下图所示,所有持久化数据存储在HDFS中,通过MapReduce任务进行选取、挖掘、回灌和抓取结果入库。
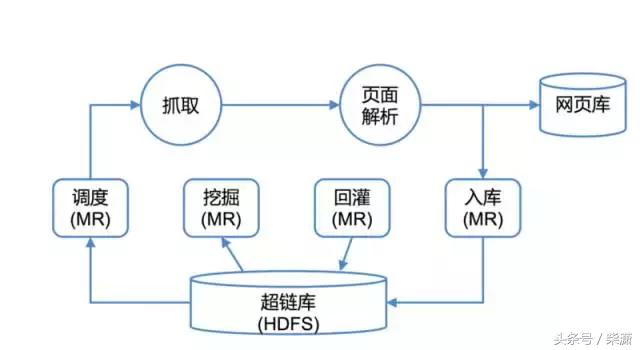
Hadoop时代的百度Spider
但这个Spider有什么问题吗?其实它的首要问题就是线性扩展的问题。很多时候大家接触到的线性扩展或者水平扩展都是一个褒义词,即用10倍的机器就能处理10倍的数据,线性增长,处理能力没有明显的下降。
但是,在这里它却变成了一个严重的问题:举个例子,在过去Spider系统每天处理1000亿链接的时候需要500台服务器,而今天互联网上的链接呈爆炸性的增长,系统每天要处理10万亿级的链接,就需要5万台服务器,这肯定是一个不可承受的代价或者成本,所以这时候我们必须得有新的解决方案,不能再做全量的处理,必须有一种增量的,只处理新链接的方式。
我们期望的处理过程如图所示。
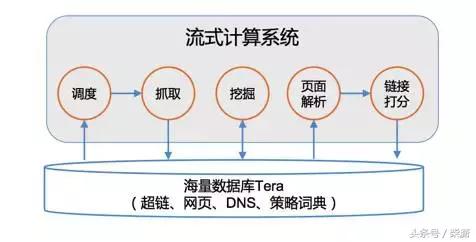
很多人看到后可能有些失望,百度Spider就这么点东西吗?其实大家仔细去想,简单代表了更更大的灵活性和更强的扩展性。它其实就是一个流式计算系统,然后系统中的每一个策略也好,或者过程也好,都是流式系统上的一个算子,比如调度、抓取、页面解析、页面打分、链接权值打分。
整套系统的核心在于数据。一方面,我们做实时数据处理,表面上完成工作的是这些算子和计算流程,而每个算子的计算都依赖与数据的输入和输出,算子的计算延迟很大程度上决定于输入数据的获取延迟,输出数据的写出延迟。算子计算的稳定性又依赖与数据的不重不丢,这些数据必须有一个持久存储,又能随时、随地获取的方式,这样才能更好的去做实时的流式的处理。
另一方面,区别于普通的流式处理,如果仅去对单个链接或网页做流式处理,常规的Strom、Flink这些框架都是可以做到的。那么,它的真正的难点是什么?其实整个搜索引擎的计算,数据之间是有依赖性的,一张网页的价值谁说了算,一部分是由所在站点的权值和路径深度决定,更多的是由指向它的链接(前链)来投票决定。
也就是说处理一张网页时其实要同时处理整个数据集里面上百处位置的状态,一张网页价值变化了,要同时更新网页上包含的所有链接对应网页的权值,同样,在判断一个链接的价值时,也可能要依赖它的成百上千个前链上的实时数据。这就要求前面提到的那个可以随时、随地访问的数据集不是一个局部数据集,而是涵盖互联网全网数据的全集。
Tera的模型与架构
百度的第三代Spider系统,它的核心在于实时的数据处理,这些实时的数据处理的主要挑战:
第一个挑战就是全量数据的数据集比较大,大概10万亿条,百PB量级。如果是冷数据,把它放在冷备存储上可以很低价的维护,但是在Spider中不可能做到这样,因为每时每刻这个数据集中的每一条都有可能被改变,要保证它被改变时随时被更新,也就是在10万亿条数据级上随时去读写。
第二个挑战就是每天新抓网页100亿,触发1万亿条链接更新,每秒属性更新近亿次,这带来的是一个量级的提升,会对底层数据库造成每秒上亿次的随机读写访问。另外搜索引擎有一个特点,就是需要做调度,底层数据访问既可以随机访问也可以顺序访问,要求底层存储里的这些数据有序,这样就可以很好的统计一个站点上到底抓了多少,我们知道我们现在控制的一个站点压力不要把这个站点压跨,所以说需要很多维度的调度。
面对这些挑战,我们给出来的解决方案就是分布式的数据库 Tera ,首先容量自不必多说,必须要达到万亿量级百P的容量,再就是它要多维度的调度,支持区间访问,方便统计,就必须是一个有序表,它最核心的点是要支持自动的负载均衡,自动扩容,自动缩容。
因为众所周知的一种情况是互联网上热点频发,经常有一些站点成为爆发状态,还有一些站点突然就消失了。还有一种情况就是业务迭代非常快,可能有些业务刚创建了表,只需要10台机器进行服务,可一旦快速扩张,可能就需要几百台机器了,你应该很快地实现这种扩容,同样当它的峰值过去后也能很快地实现缩容。
除此之外,这个系统还要有一个多版本特点。有这么一种情况,上线一种新的策略或者新的活动时,因为有些地方逻辑出了个BUG,把数据库写坏了,这时候需快速恢复或者止损,就只有一个办法,就是将整个数据库状态回滚。此外,这个数据库还有一个特性,比如列存储、分布式事务,都是一些比较扩展性的特征。
该数据库的核心数据模型是三维的,除了行和列还有时间的维度,通过这个维度我们可以存储网页或普通的历史数据,这样一方面方便我们去做历史行为的挖掘,另一方面它也实现了刚才我说的回滚,可回滚到昨天前天或者某个时间的特殊状态。
第二点就是说这个数据库它的分片(sharding)方式,是一个全顺序按行去切分的,也就是说行与行之间绝对有序,然后在中间把它切开以后分到不同的区间上去,区间与区间之间也是有顺序的。
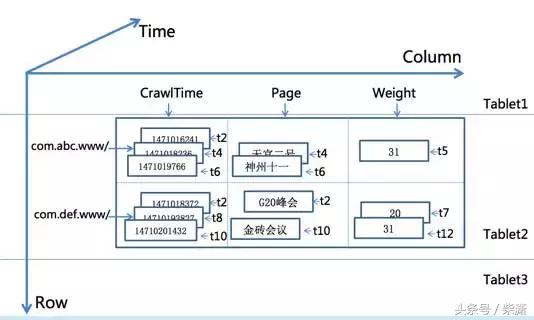
按行切分成多区间(Tablet)
在这里大家可以看到它的一个简化的架构图,我们把整个数据表按行去切分层多个Tablet,或者切分为一个子区间,每一个子区间都可以在TabletServer上服务,这张图其实还有一个核心点,我想让大家注意一下就是它的一个核心设计的思想在于它把所有的数据全部放在底层的分布式文件系统,这里面提到的BFS上,这样整个数据库都是无状态的,它的所有的数据全部是落在分布式文件系统上的,这就为了后面的很多特征的实现提供了可能。
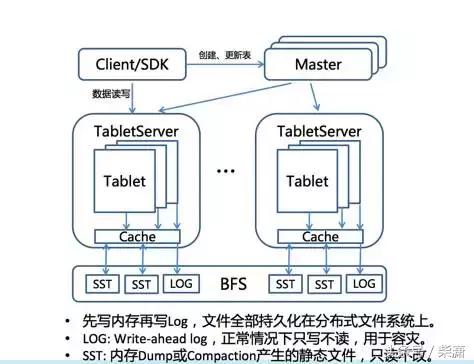
Tera架构
这个具体做的事就是一件事,就是把随机写转换成顺序写,让我们对整个海量的顺序这种随机读写的访问成为了可能,它把随机写转换成顺序写的算法也很简单,他通过先写Log再写内存,等内存写到一定量的时候,把内存成为一种静态文件,这种方式去实现了支持顺序写,还能够保证最后下去的数据有序,然后再去后台,进行垃圾收集,保证整体的数据量有限的膨胀。
以上就是它的架构了,那么它给为我们带来什么呢?首先,它实现了在流式的处理系统中做到海量数据随时随处可用,上层的计算系统有很大的空间,有PB级的内存,统一的地址空间,几乎你在任何一台机器上想存的数据都是可以存下。再下面就是百PB级存储,不用担心持久化,你不用担心数据丢失,它做到了数据写下去以后,任何其他机器实时可读,写入立即可读。
很多人都用过Hbase,下面列一下它和HBase的一些相同点和不同点。
相同点有两个:
Bigtable数据模型
开源
不同点有三个:
一是可用性,这个系统最核心的一点就是说我们通过提升可用性,来解决了在我们上层实时业务中能够真正去支持实时业务。这一点怎么去做到的,后面会详细介绍。它主要解决了区间热点的问题,不会因为某些区间热点导致区间不可服务。
二是吞吐和延迟,Tera是C++实现,效率更高的同时,没有内存GC,不存在延迟不稳定的问题。
三是扩展性,HBase可以做到数百台,而它可以做到数千台。
以上这些我们怎么做到的?首先就是快速负载均衡,其实更核心的一个点在于热点区间的分裂,就是说我们如果由于业务的变化,或者说上层用户行为的变化,导致一个区间变成了一个热点区间,那么我们会在很快的时间内把它分裂开,一个区间分裂成多个区间,然后把其中的一部分迁移到比较空闲的机器上,通过这种方式实现了快速的负载均衡。这个快速负载均衡是通过文件引用的方式去实现的,也就是说不论是区间的分裂还是区间的迁移都是没有任何数据拷贝的,因为数据全部分布在底层的分布式系统上的。
在此大家也会想到其实HBase也是有这个功能,它热点区间也是可以提供这种在线的分裂,但是这里往往会引入这么一个问题,就是原来0这个区间是个热点的时候把它分为1和2,很快2这个区间又成为热点了,你把2再分成3和4,如果现在4这个区间又成为热点又怎么办?
在HBase上敢这么分吗?你刚开始初期创建了一个表,有一千个分片,那么可能两天三天以后就变成一千万个分片,因为不停分裂下去,分片数就完全不可控了,所以这里负载均衡核心问题不在于快速分裂,而在于很好的处理分裂后的碎片问题,能做到一旦一个区间不再是热点区间了,能瞬间合并。
所以在此要强调一点,能快速合并才能做到敢分裂,这才是一个真正的解决热点问题的方式。在这一点上TabletServer系统就是区间快速迁移,区间快速合并,仅有元数据变更,代价小,时间短,全自动,无人工干预。
表面上我们解决热点问题的方式是用快速的区间分裂和迁移去做的,实际上这个问题本质上是通过什么方式解决的呢?这里通过一张图去展示这一点,即连续区间本身是存在一台机器上服务的,但是这一个区间内部可能会有很多这种SST这种静态文件,这种静态文件实际上在底层分布式文件系统上是散在几百台甚至上千台机器上的,这种非常强的随机读能力去解决的热点问题,也就是说虽然你看到了一个区间是在一台机器上服务,实际上它的所有数据文件,所有你读它产生的IO都会被打散到底层的几百台机器上去。
这里有一个背后的英雄,就是百度文件系统BFS,这套文件系统的设计非常复杂,但是它核心是解决了HDFS的扩展性以及延迟的问题,可以真正面向实时应用,做到持续可用、低延迟。这个文件系统当前也已经开源。
系统构建中的经验与教训
下面介绍一些在构建上层业务系统、底层分布式系统中积累的一些经验。
第一个经验,是采用分层设计的原则,如下图所示。
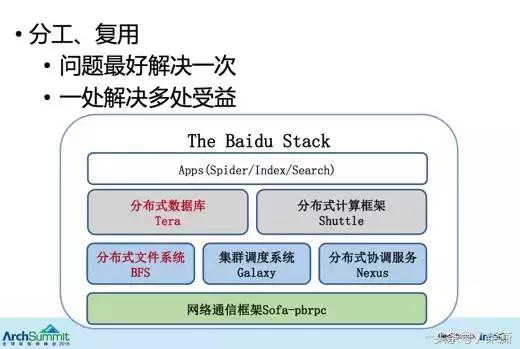
工业实践-分层设计
从图中可以看到当前百度网页搜索的软件栈,最底层的网络框架包含了分布式文件系统、集群调度系统和分布式协调服务;再上层是数据库;再上层才是实际的业务。
这些技术系统都是一层一层堆上去的,比如说最底层的网络通信框架,所有的网络问题,包含Socket编程的封装,网络的流量控制,跨地域的链接优化,全部会封装在这一层。上层用它开发分布式文件系统时,就完全不需要考虑网络问题、流量控制问题了,只需要关注分布式文件系统的逻辑就可以了。
然后,把所有数据持久化甚至IO相关的一些工作全部放在分布式文件系统这一层。在构建上层的分布式数据库、分布式数据处理框架,乃至上层业务系统的时候,都不再需要考虑数据持久化的问题,也不需要考虑IO持久能力的问题。这样就能让数据库可以做到完全无状态的。大家可能接触过很多数据库,没有任何一个数据库系统可以做到完全无状态的。这个完全无状态甚至包含cache无状态。
也就是说这种分层设计带来一个最大的好处,就是任何问题在一处解决了,很多处都会受益,同样问题在一个地方解决一次就够了,上层系统完全不需要考虑网络问题、丢数据的问题、IO能力的问题。
第二个经验,是要去为可用性设计,要能做到容错。通常我们计算可用性可以用:可用性=(总时间-故障数*恢复时间)/总时间。很多工程师和架构师做系统设计的时候,会把很多精力放在降低故障发生的频率,降低故障发生的机会,尽量让系统不要出故障,以这种方式来提高可用性,而在我们这套设计思想里,我们不通过这种方式提高可用性,为什么?
因为故障不可避免。假设我们单台服务器的平均故障间隔时间是30年,在市场上你是绝对买不到这种30年都不会坏的服务器的,但我们假设你有这种服务器,你去搭建一个万台的集群,你在使用这个集群的过程中会发现每一两天就会坏一台机器。也就是说无论你的服务器再好,都不能避免故障。
我们提高可用性的思路就是降低故障恢复的时间,平常所说的几个9,就是总请求数减去故障数,乘以故障影响的数,通过这套思想,这套分布式数据库做到比以前高一个9,就在于故障恢复时间。
第三个经验,是要去为低延迟设计。因为我们现在整个上层的业务系统都在从批量到实时过渡,我们要做实时系统,实时系统很大程度上对延迟有很高的要求,backup request是个很好的选择,我希望他99.9分位的延迟不要超过10毫秒。我期待这个服务平均1毫秒返回,如果2毫秒还没返回,我就再发一个请求到备份节点,这样来降低延迟的长尾。
另外是慎用自动GC的语言,实时处理,大量小请求,频繁触发STW,服务无响应,不必要的failover,导致整个系统不稳定,所以尽量不要用这种自动GC语言。剩下可选的语言可能就不多了,所以我们这套系统选择用C++开发。
未来工作
这套系统未来的工作是走出百度、走向社区。今天,百度这一套核心的分布式系统已经完全开源了,我们也把所有的开发、codereview和版本的发布,全部放在GitHub上,外部提交的代码已经在驱动百度的这套搜索了。

[超站]友情链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
排名
热点
搜索指数
- 1 中秘关于深化全面战略伙伴关系的声明 7945709
- 2 三胎宝妈在月子会所充55万成股东 7960475
- 3 大爷要10元切糕结果切完变60元 7851169
- 4 秘鲁总统:已备美酒 欢迎光临! 7745057
- 5 俄罗斯开出停战先决条件 7680757
- 6 俄媒:苏-57比中国歼-35更强 7588927
- 7 “退钱哥”说不退钱了 7458120
- 8 孙杨与妻子同游环球影城 7357679
- 9 来珠海航展只为疯狂扫货?沙特澄清 7208197
- 10 10月份主要经济指标回升明显 7180129

