
























 芝恩㱏
芝恩㱏
 分享文章
分享文章
新闻分类
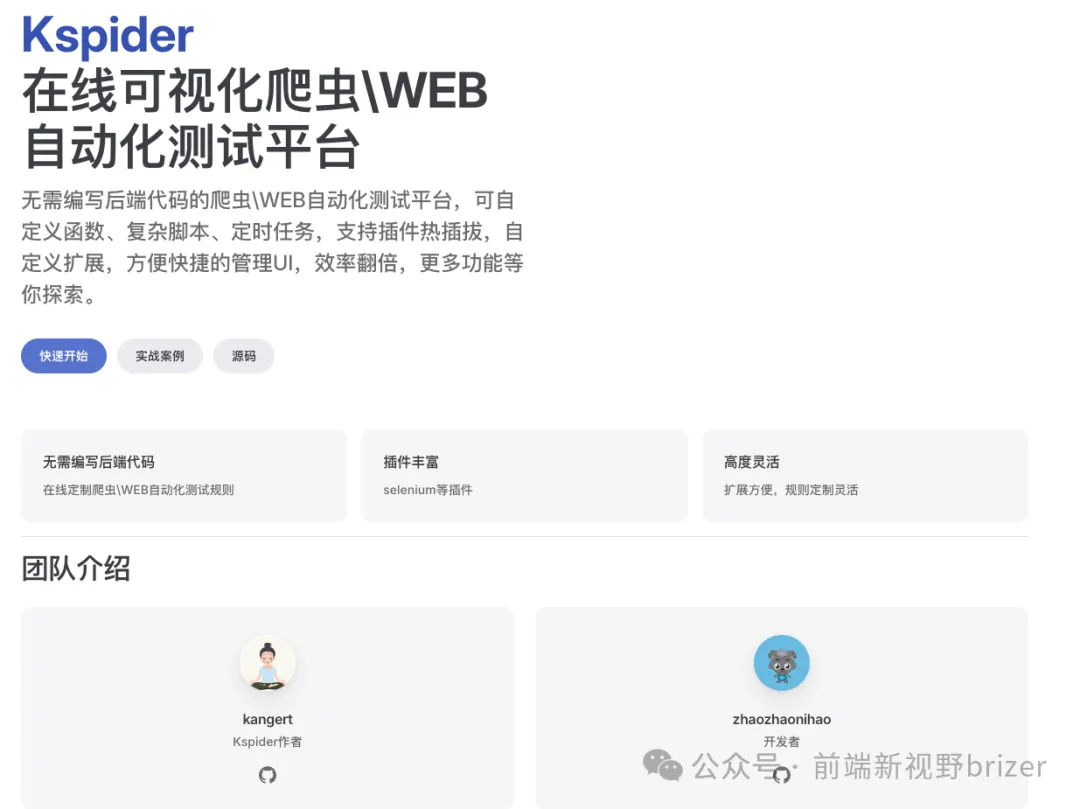
Kspider:超级给力的图形化爬虫平台
Kspider 是一个无需编写代码即可定义爬虫流程的图形化平台,专为需要高效抓取网页数据的用户设计。
这个平台不仅适用于数据抓取,还可用于 WEB 自动化测试。通过简单的图形界面操作,用户可以轻松配置并执行复杂的爬虫任务。
软件特点
Kspider 的亮点在于其强大而全面的功能。以下是一些主要特点:
• 多种选择器支持:如 xpath 和 css 选择器。
• 丰富的数据提取方式:支持选择器提取、正则提取、json 提取等。
• Cookie 自动管理:无需手动处理 Cookie。
• 动态页面抓取:支持抓取由 JavaScript 动态渲染的页面。
• 代理支持:提供多数据源和代理配置功能。
• 内置常用函数:包括字符串、日期、文件处理和加解密函数。
• 数据存储:支持将结果保存至数据库、CSV 文件等。
• 插件扩展:支持自定义执行器和函数。
• 任务日志和调试:提供可视化调试和任务日志记录。
• 执行方式多样:支持同步和异步执行,以及自定义 JS 脚本引擎。
• 产物下载:方便下载抓取结果。
优势对比
相比其他爬虫工具,如 Scrapy 和 Beautiful Soup,Kspider 具有以下显著优势:
• 图形化界面:Kspider 通过拖拽操作即可完成配置,无需编写复杂代码,而 Scrapy 和 Beautiful Soup 需要大量的手动编码。
• 集成度高:Kspider 除了抓取数据,还支持数据存储和 WEB 自动化测试,而 Scrapy 和 Beautiful Soup 功能相对单一。
• 易用性强:Kspider 的用户界面友好,配置和执行流程简单直观,而 Scrapy 和 Beautiful Soup 在使用上相对复杂。
部署与使用
部署 Kspider 非常简单。你只需从 GitHub 上克隆项目到本地,按照 README.md 文件中的指示进行设置。这通常包括安装依赖项、构建项目以及配置相关参数。

[超站]友情链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接





排名
热点
搜索指数
- 1 总书记鼓励民企“做强做优做大” 7909036
- 2 俄或同意用3000亿美元重建乌克兰 7933996
- 3 200斤女生cos石矶娘娘被小孩当真 7891446
- 4 “用工忙”折射中国经济“开门稳” 7745594
- 5 俞敏洪谈王兴兴:他是个天才 7619359
- 6 女子新婚遭家暴失明:在等伤残鉴定 7544506
- 7 涉农补贴公示泄露6000多农民隐私 7493886
- 8 李嘉琦演技 7307010
- 9 马斯克投的飞行汽车试飞 200万一辆 7264541
- 10 王兴兴:国内校园学的很多东西太老 7178710
