
























 嗜宠而娇
嗜宠而娇
 分享文章
分享文章
新闻分类
DdddOcr自动打码通用验证码自动识别库
在Python爬虫中,或者使用POST提交的过程中,往往需要提交验证码来验证,除了人工打码,付费的api接口(打码接口),深度学习识别验证码,当然还有适合新人使用的OCR验证码识别库,简单的验证码是可以完全实现自动打码的,比如下面本渣渣分享的通用验证码自动识别库:ddddocr(带带弟弟OCR)!
DdddOcr库安装
pip install ddddocr
想要更快,使用国内镜像安装:
pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple
DdddOcr库用法
参数说明 DdddOcr 接受两个参数
参数名默认值说明 use_gpu FalseBool 是否使用gpu进行推理,如果该值为False则device_id不生效 device_id 0 int cuda设备号,目前仅支持单张显卡
classification 参数名默认值 说明 img 0 bytes 图片的bytes格式

参考源码:
import ddddocrocr = ddddocr.DdddOcr()with open('code.png', 'rb') as f: img_bytes = f.read()res = ocr.classification(img_bytes)print(res)
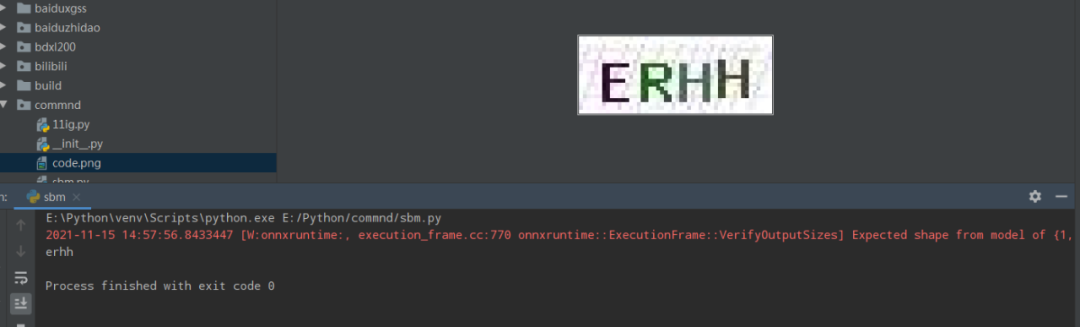
DdddOcr实战
网站评论提交
url:https://www.feifeidm.com/Play/10919-0-0.html
验证码地址:https://www.feifeidm.com/include/vdimgck.php?r=0.7145461007261535
参考源码:
import ddddocrimport requestsheaders = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}code_url="https://www.feifeidm.com/include/vdimgck.php?r=0.7145461007261535"r=requests.get(url=code_url,headers=headers,timeout=5)with open('code.png','wb')as f: f.write(r.content) print("下载验证码成功!")ocr = ddddocr.DdddOcr()#with open(r'C:\Users\Administrator\Desktop\验证码识别\code.png', 'rb') as f: #img_bytes = f.read()img_bytes=r.contentres = ocr.classification(img_bytes)print(res)
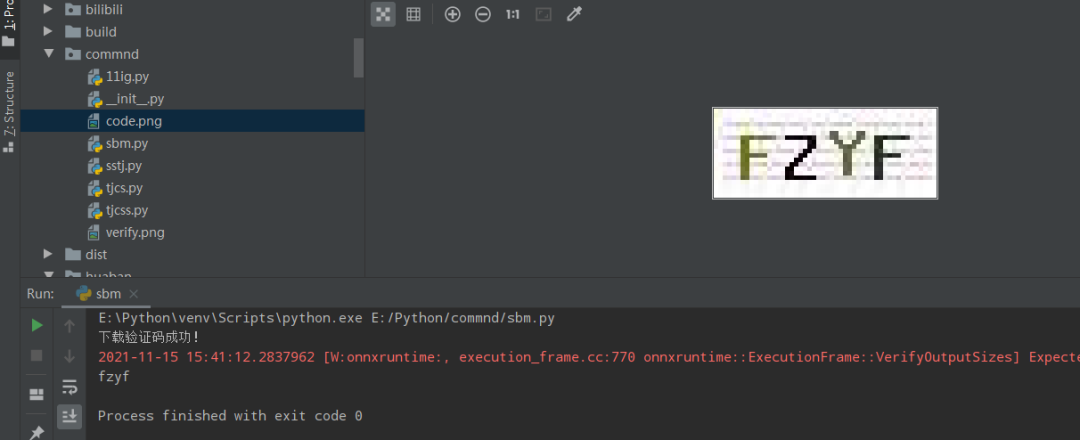
搜狗快照删除/提交
url:http://fankui.help.sogou.com/index.php/web/web/index?type=2
扩展:其他适合新人的ocr识别库
pytesseract ytesseract需要配合安装在本地的tesseract-ocr.exe文件一起使用,Tesseract Ocr文字识别,需要注意的是安装时一定要选中中文包,默认是只支持英文识别。
库安装:
pip install pytesseract
库用法:
import pytesseractfrom PIL import Imagetext = pytesseract.image_to_string(Image.open(code.png"))print(text)
PaddleOCR addleOCR是百度开源的一款基于深度学习的ocr识别库,对中文的识别精度相当不错,可以应付绝大多数的文字提取需求。
库安装:需要依次安装三个依赖库,安装命令如下,其中shapely库可能会受系统影响安装报错。
pip install paddlepaddlepip install shapelypip install paddleocr
库用法:
ocr = PaddleOCR(use_angle_cls=True, lang="ch")# 输入待识别图片路径img_path = r"code.png"# 输出结果保存路径result = ocr.ocr(img_path, cls=True)for line in result: print(line)from PIL import Imageimage = Image.open(img_path).convert('RGB')boxes = [line[0] for line in result]txts = [line[1][0] for line in result]scores = [line[1][1] for line in result]im_show = draw_ocr(image, boxes, txts, scores)im_show = Image.fromarray(im_show)im_show.show()
easyocr github上一万多个star的开源ocr项目,支持80多种语言的识别,识别精度超高。
库安装:
pip install easyocr
库用法:
import easyocr#设置识别中英文两种语言reader = easyocr.Reader(['ch_sim','en'], gpu = False) # need to run only once to load model into memoryresult = reader.readtext(r"code.png", detail = 0)print(result)
muggle_ocr muggle_ocr是一款轻量级的ocr识别库,从名字也可以看出来,专为麻瓜设计!使用也非常简单,但其强项主要是用于识别各类验证码,一般文字提取效果就稍差了。
库安装:
pip install muggle_ocr
库用法:
import muggle_ocr# 初始化sdk;model_type 包含了 ModelType.OCR/ModelType.Captcha 两种模式,分别对应常规图片与验证码sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)with open(r"code.png", "rb") as f: img = f.read()text = sdk.predict(image_bytes=img)print(text)

[超站]友情链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接





排名
热点
搜索指数
- 1 习近平的科技情怀 7973816
- 2 美国反对称俄罗斯为“侵略者” 7909758
- 3 在房产证上加名也可能无法分到房产 7834547
- 4 创新服务“换”出消费新活力 7735526
- 5 陈凯歌说太假了全是套路 7619450
- 6 王兴兴:国内校园学的很多东西太老 7564977
- 7 特朗普:泽连斯基是否谈判不重要 7446886
- 8 昆明一电梯疑故障冲顶致业主身亡 7339056
- 9 孙颖莎热身动作像极了哪吒 7249197
- 10 派出所副所长被指徇私 家属质疑 7132805
