
























 草莓羽衣
草莓羽衣
 分享文章
分享文章
新闻分类
OpenAI员工公开指责Grok3
IT之家 2 月 23 日消息,本周,OpenAI 的一名员工公开指责埃隆・马斯克旗下的 xAI 公司,称其发布的最新 AI 模型 Grok 3 的基准测试结果具有误导性。对此,xAI 的联合创始人伊戈尔・巴布什金(Igor Babushkin)则坚称公司并无不当。
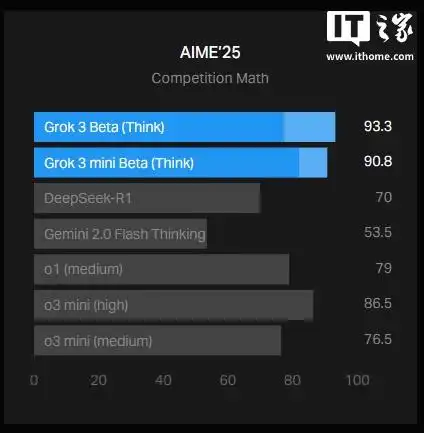
xAI 在其博客上发布了一张图表,展示了 Grok 3 在 AIME 2025(一项近期邀请制数学考试中的高难度数学题集)上的表现。尽管一些专家质疑 AIME 作为 AI 基准的有效性,但 AIME 2025 及其早期版本仍被广泛用于评估模型的数学能力。
IT之家注意到,xAI 的图表显示,Grok 3 的两个版本 ——Grok 3 Reasoning Beta 和 Grok 3 mini Reasoning—— 在 AIME 2025 上的表现超过了 OpenAI 当前最强的可用模型 o3-mini-high。然而,OpenAI 的员工很快在 X 平台上指出,xAI 的图表并未包含 o3-mini-high 在“cons@64”条件下的 AIME 2025 得分。
“cons@64”是指“consensus@64”,即允许模型在基准测试中对每个问题尝试 64 次,并将出现频率最高的答案作为最终答案。可想而知,这种方式往往会显著提升模型的基准测试分数,如果图表中省略这一数据,就可能让人误以为某个模型的表现优于另一模型,而实际情况未必如此。
在 AIME 2025 的“@1”条件下(即模型首次尝试的得分),Grok 3 Reasoning Beta 和 Grok 3 mini Reasoning 的得分低于 o3-mini-high。Grok 3 Reasoning Beta 的表现也略低于 OpenAI 的 o1 模型在“中等计算”设置下的得分。然而,xAI 仍在宣传 Grok 3 为“世界上最聪明的 AI”。
巴布什金在 X 平台上辩称,OpenAI 过去也曾发布过类似的误导性基准测试图表。尽管这些图表是用于比较其自身模型的表现。
在这场争议中,一位中立的第三方重新绘制了一张更为“准确”的图表:
但正如 AI 研究员内森・兰伯特(Nathan Lambert)在一篇文章中指出的,或许最重要的指标仍然未知:每个模型达到最佳分数所需的计算(和金钱)成本。这恰恰表明,大多数 AI 基准测试在传达模型的局限性和优势方面仍然存在很大的不足。

[超站]友情链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接





排名
热点
搜索指数
- 1 从这场会见 看中国信心与机遇 7933235
- 2 李嘉诚卖港口将被审查 外交部回应 7944183
- 3 夫妻俩备孕无果到烈士陵园求子 7843748
- 4 AI时代 创作何为 7775230
- 5 距深圳市约170公里发现1亿吨油田 7667745
- 6 世界那么大 只有广西在放假 7589554
- 7 王玉雯杨玏百科关系解除 疑似分手 7400814
- 8 河南一枯井发现近百名烈士遗骸 7347868
- 9 住宅新规:新建住宅4层及以上装电梯 7258785
- 10 钟南山提醒:不要为节约吃剩饭剩菜 7180413
